När man sätter upp en supportorganisation krävs en del planering samt att man förstår naturen av en supporverksamhet. Exakt vad som krävs beror på typ av verksamhet, tillhandahållna tjänster, storlek på företaget, kundgrupper, etc. En startup kan ha andra behov än ett stort väletablerat företag. I denna artikel går vi igenom saker du behöver tänka på när du sätter upp, eller genomför förbättringsarbete, av din egen supportorganisation.
Målgruppen för denna artikel är personer som ska sätta upp en supportverksamhet, Help Desk, Service Desk, etc. i ett litet (< 50) till mellanstort (< 250) företag. Vi har dock lagt in lite saker att tänkte på för större företag i slutet av artikeln. För definitioner av "Help Desk" och "Service Desk", se denna artikel.
Terje Hatt, tidigare global chef över Fujitsu Customer Service och SEB Service Desk, för tillfället konsult på Daymark AB, är medförfattare till denna artikel.
Små till medelstora företag
SLA (Service Level Agreement)
SLA är ett avtal man gör med kunden. I detta avtal finner man responstider, åtgärdstider, datum och tidpunkter för servicefönster, överenskomna tillgänglighetstider för tillhandahållna tjänster, etc. Exempelvis kan ett SLA specificera responstiden för en incident till 30 min för kontorstid men 2 timmar utanför. Avtalet kan också definiera att en levererad IT-tjänst ska ha en tillgänglighet på 97,5% av alla timmar på dygnet under en mätperiod på ett kalenderår, exkluderat servicefönster.
SLA är en av en viktig grundpelare för att veta vad som förväntas av supportverksamheten så att denna kan organisera sig efter dessa krav.
Definiera tydliga och mätbara mål för supporten
Om du definierar mål för din supportverksamhet kan du planera bemanning, utbildning och nödvändiga processer för att uppnå målen. Alla mål måste inte finnas med i ett SLA för en supportverksamhet.
Vill du sätta upp en supportverksamhet som bara dispatchar inkomna ärenden till rätt grupp som kan hjälpa kunden? Detta är normalt för ett Call Centre vars policy brukar vara "Catch and dispatch". En "Catch and dispatch"-funkion har låg lösningsgrad och kan ha målet att dispatcha så många ärenden som möjligt. Personalen i en sådan funktion kan behöva utbildning i hur man kommunicerar med kunder och hur man hanterar "svåra" kunder.
Ska ni sätta upp ett supportfunktion med hög lösningsgrad? Då är det ett "Competence centre", eller normalt kallat Helt Desk eller Service Desk, ni sätter upp. Förutom samma utbildning som personalen i en "Catch and dispatch"-funktion behöver personalen i en sådan funktion ha domän-/expertkunskap om de ärenden som kommer in.
Inom de olika typerna av funktioner kan man sätta olika typer av mål. För "Catch and dispatch" kan målet vara hur många samtal som ska hanteras. Inom "Competence centre" kan det vara lösningsgrad av inkomna ärenden.
Definiera supportkanaler och informera användarna om hur de kontaktar supporten
Hur ska du ta emot supportförfrågningar från användarna? Detta spelar roll för hur du ska utrusta supportpersonalen. I de fall då kunden ska kunna ringa in måste supportpersonalen ha bra headsests för att både kunna skriva och prata samtidigt. Ska kunden endast använda email så behövs ett ärendehanteringsverktyg, som stödjer kommunikation från kunden endast med hjälp av email, för att administrera inkomna ärenden. Ett ärendehanteringsverktyg är nödvändigt oavsett hur användarna kontaktar supporten då allt måste administreras på ett sätt så att man inte tappar ärenden mellan stolarna.
Nedan följer några normala kanaler för kommunikation:
- Email
- Ärendehanteringsverktyg (både för email och när användaren själva kan logga in)
- Telefon
- Webbformulär (för att skicka en förfrågan från en hemsida)
- Facebooksida
- Twitter
Gör det lätt för användarna att hitta information om hur man kontaktar supporten. Normalt så tittar användarna på din hemsida för att få information om hur man kontaktar supporten. Presentera gärna denna information på första sidan.
Sätt förväntningarna hos kunden/användarna
Om du har en businesss-to-business (B2B) supportfunktion så har du troligtvis ett SLA som definierar responstider och kanske åtgärdstider. Har du en business-to-consumer (B2C) supportfunktion så kanske inte det är fallet.
Hantering av förväntningar hos B2B
Förväntningarna mellan företag är oftast definierat i ett SLA, som vi har diskuterat ovan.
Det är en sak att ha ett SLA definierat och signerat, en annan sak att nödvändiga personer ska veta vad erat SLA säger och därmed vilka förväntningar som finns. Tyvärr händer det att personer som borde veta om, exempelvis, responstider inte gör det. Organisationen måste utbilda nödvändig personal om förväntningarna som finns från dem som leverantör och vad kunden har blivit lovad.
Den här informationen ska vara lätt tillgänglig oavsett tidpunkt. Om det är ett enkelt SLA kan information finnas tillgänglig på intranätet. Om det är ett stort företag med många olika tjänster, kunder och avtal kan man lägga information i en tjänstekatalog och/eller CMDB (Configuration Management Database) där varje tjänst eller server har sitt avtal kopplat.
Om det ändå inte finns något SLA kan det vara bra att definiera vilka nivåer verksamheten ska mäta sig mot för att kunna tillhandahålla någon nivå av kvalitet på supporttjänsterna. Obegränsad svarstid på en förfrågan är inte ett alternativ...
Hantering av förväntningar hos B2C
Denna sektion kan också gälla intern support i stora organisationer.
När en kund ringer supporten så förväntar de sig (eller hoppas iaf...) på ett snabbt svar. Tyvärr är det inte alltid så. Vad ett företag, eller myndighet, kan göra är att tillhandahålla information från deras växel. När man ringer Skatteverket får men ett meddelande i telefon liknande detta: "Du har nummer 123 i kön. 95 agenter jobbar på att så snabbt som möjligt hjälpa dig". Tänk om man endast hade fått informationen "Du har nummer 123 i kön", hade du väntat kvar i telefonen? Genom att presentera hur många som jobbar i supporten, eller estimerad väntetid, får personen en uppfattning om hur länge de kommer behöva vänta. Varför inte presentera denna information bredvid supportnumret på hemsidan?: "För närvarande har vi 12 min väntetid".
Liknande sätt att sätta förväntningarna kan användas om användaren mailar till supporten eller skickar in frågan vi ett formulär på hemsidan. Ett automatiskt svar kan skickas ut som informera om förväntad tid innan de får hjälp. Detta skulle kunna reflektera SLA som företaget har definierat även om det inte är ett signerat avtal. Eller så kan det finnas någon intelligens som i systemet som räknar ut hur långa svarstiderna är för tillfället.
Samma gäller här som för B2B, finns det inget SLA är det bra att definiera vilka svars- och åtgärdstider som förväntas för att kunna tillhandahålla en viss kvalitet på supporttjänsten och för att ha något att sätta förväntningarna mot.
"Knowledge management"
Bra kunskapshantering kan markant minska arbetsbelastning för supportpersonal samt även svars- och åtgärdstider på supportfrågor.
Kunskap kan hanteras på olika sätt:
Dokumentera återkommande uppgifter - Samma typ av supportfrågor kan återkomma i en supportverksamhet. Dokumentera dessa, informera om dessa och gör dessa tillgängliga för supportpersonalen så inte nästa person måste uppfinna hjulet igen. I bästa fall kan man automatisera hur dessa frågor löses, men det är inte fokus för denna artikel.
Driftstatus - Om det för tillfället är driftproblem kan man lägga upp information om detta dit användarna vänder sig för att få support (ex. intranätet, supportportal, etc.). Om de ser att det finns information om driftstörningar så kanske de väljer att inte registrera ett ärende och därmed sparas en del arbete för supportpersonalen. Man kan också proaktivt skicka ut information om pågående störningar till användarna genom att använda mail- eller SMS-listor. Ytterligare sätt kan vara att presentera information för användare baserat på vad de skriver när de ska registrera ett ärende via ett webbformulär. Om det finns pågående störningar och man kan matcha det med vad användaren skriver i webbformuläret så väljer kanske användaren att läsa denna information istället för att skapa ett nytt ärende.
Supportartiklar - Du kan tillhandahålla olika typer av artiklar till dina användare. Dessa bör finnas tillgängliga i en supportportal. Baserat på vad en användare skriver när de ska registrera ett ärende så kan man matcha det med de artiklar som finns och presentera ett urval. Detta kan vara artiklar om workarounder för kända fel, användarguider, etc. Comaround har ett bra verktyg för detta där många av supportförfrågningar kan hanteras innan supportpersonalen kopplas in. Verktyget kommer med massor av färdiga användarguider för, exempelvis, Windows OS, MS Office, olika mobiltelefoner, mm.
Registrera en supportförfrågan
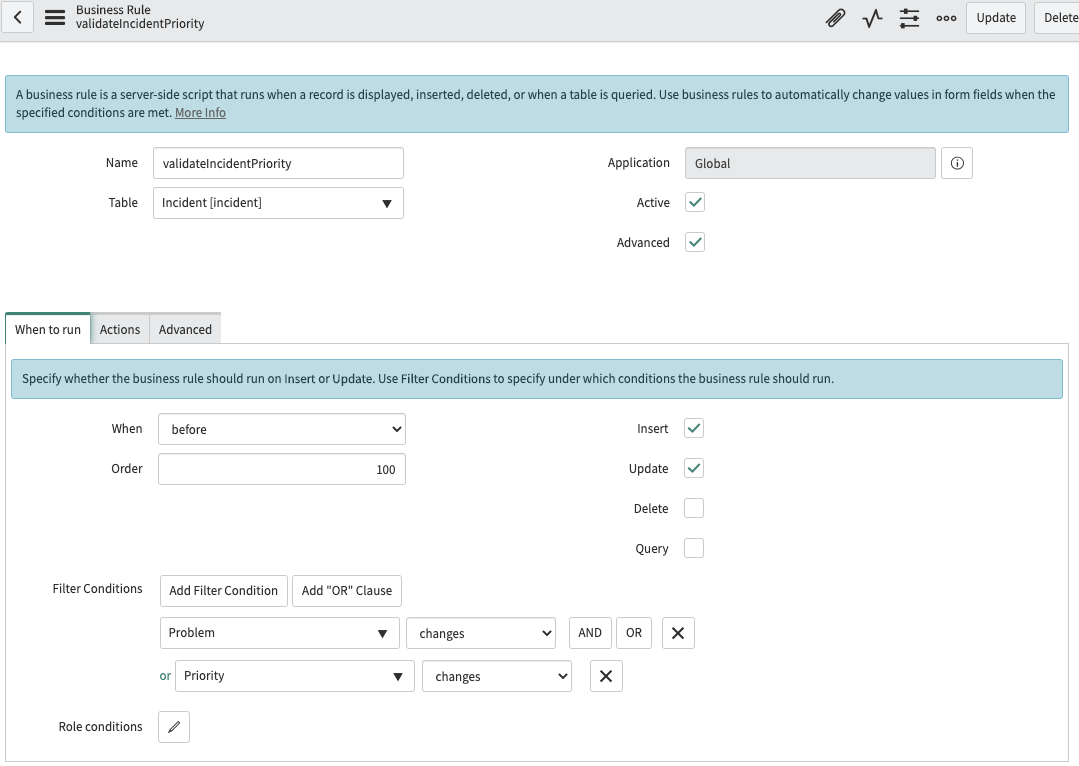
För att tillhandahålla en god support är ett ärendehanteringsverktyg nödvändigt. Vilken typ av ärendehanteringsverktyg som ska tillhandahållas hänger på vilken typ av supportverksamhet man satt upp. Läs denna artikel för att få information om olika typer av verktyg.
Du använder detta verktyg för att hålla ordning på kundernas supportärenden. All information och kommunikation sparas i ett sådant verktyg. När en annan supportperson tar över ett annat ärende finns all information sparad så denne kan fortsätta där den första slutade utan att göra ett detektivarbete för att ta reda på vad som hänt.
Information som sparas i ett sådant verktyg kan användas för statistisk uppföljning. Exempelvis kan man identifiera olika områden eller system som behöver extra fokus. Om det exempelvis är ovanligt många incidenter registrerade på ett specifikt system så måste man kanske reda ut varför och åtgärda problemet. Har man en växande trend av antal ärenden måste man vidta åtgärder för att hantera denna växande mängd.
Ett par olika exempel på ärendehanteringsverktyg listas här:
ServiceNow - I princip det enda riktiga alternativet om man vill ha ett mycket kraftfullt, kompetent och anpassningsbart verktyg med processtöd idag med (jag kanske inte är helt objektiv här...). Tillhandahålls som tjänst från molnet.
Freshdesk - Enkelt ärendehanteringsverktyg. Tillhandahålls som tjänst från molnet.
Zendesk - Enkelt ärendehanteringsverktyg. Tillhandahålls som tjänst från molnet.
Stora företag
Det finns lite mer att tänka på för större organisationer (>250 anställda) som vi vill också vill presentera. Beroende på verksamhet kan detta så klart vara intressant för mindre företag också.
OLA (Operational Level Agreements)
OLA kan användas i större verksamheter där supporten är beroende av interna enheter för att kunna leverera sina tjänster. OLA är egentligen bara ett internt SLA mellan olika interna enheter.
Det är viktigt att ett OLA mappas till de SLA som skrivs med kunden. Ett OLA kan inte ha en svarstid på att den interna enheten ska börja jobba inom 2 timmar om SLA mot kunden har definierat svarstiden till 1 timma.
Tillsätt ansvariga för processer och styrning
För att sätta upp en supportverksamhet som är anpassat till uppsatta mål måste en person som ansvarar för styrningen tillsättas. Inom ansvaret för denna person ligger att definiera strategier för hur supportverksamheten ska struktureras. Detta kan bl.a. innehålla ansvar för att hur supporten ska organiseras, vilka verktyg som ska användas, utbildning av personal, supportkulturen, etc. Det är även den som ansvarar för styrningen att etablera strategier för arbetet med processer, vilket tar oss till nästa punk, processansvariga.
I större verksamheter finns det ofta en processansvarig för varje process. Denna person ansvarar för att definiera processen, anpassa den när verksamheten växer och mognar, definiera krav på supportverktyg som stödjer processen, etc. Den processansvariga är inte den som exekverar själva processen. Istället hjälper den ansvariga verksamheten i användandet av processen. Processen ska byggas in i de arbetssätt som personalen använder sig av. Det är processägarens ansvar att utbilda personalen i hur de olika processerna fungerar.